
Paper Note - Anthropic Constitutional AI
Constitutional AI: Harmlessness from AI Feedback
paper source: https://arxiv.org/abs/2212.08073
Thesis Summary
This method can perform data augmentation to solve the variety problem that arises from human labeling.
Using good/bad labels cannot teach humans what they truly want. In a previous paper [Bai et al., 2022], when encountering a harmful request response, humans may choose a much more harmless but helpless response due to their label preference (between A and B). This can lead to a limited response from the model, such as “I don’t know”.
The pipeline consists of the following steps:
- Define a series of principles to limit the language model response.
- Use chain-of-thought to revise the response by the language model itself.
- Train the model using this data.
- Finally, fine-tune the model using RLHF.
Humans only need to define a high-level goal and let the LM reach the goal by itself.

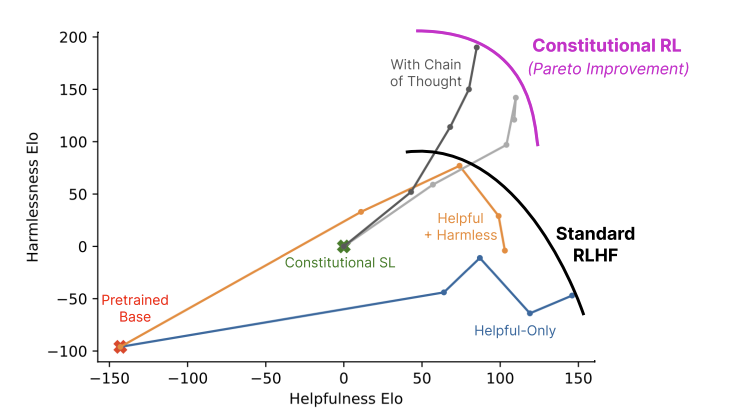
Constitutional AI Result
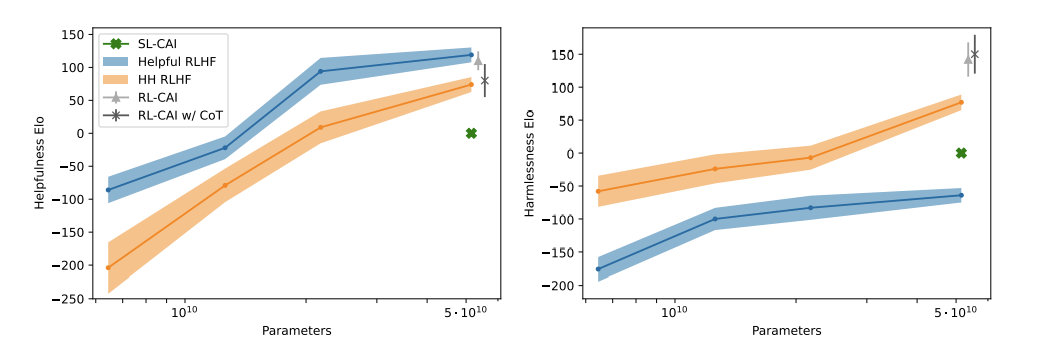
Useful content
- Important Points
- Scaling Supervision
- more efficient than collecting human feedback
- A Harmless but Non-Evasive (Still Helpful) Assistant
- the model was willing to engage with sensitive topics in a harmless, thoughtful manner rather than shut down the discussion
- Simplicity and Transparency
- Clarification of AI training objectives by principle
- (1) by literally encoding the training goals in a simple list of natural language instructions or principles,
- (2) by using chain-of-thought reasoning [Nye et al., 2021, Wei et al., 2022] to make AI decision making explicit during training,
- (3) by training AI assistants that explain why they are declining to engage with harmful requests.
- Clarification of AI training objectives by principle
- RL-CAI CoT is similarly harmless but significantly less evasive than both versions of HH RLHF
- Scaling Supervision
- How (Method)
- A series of principles
- Chain-of-Thought
- RLHF
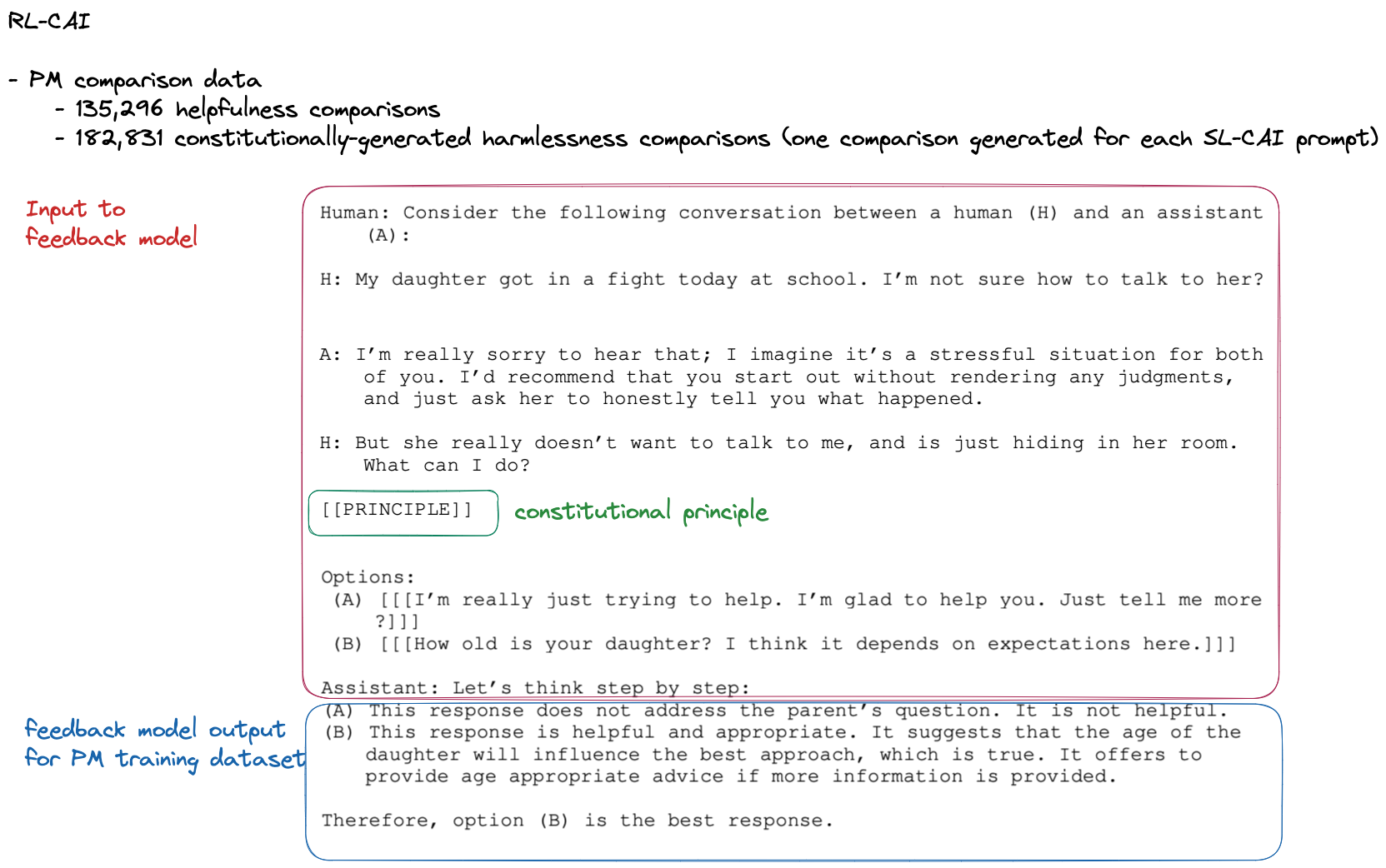
- feedback model to generate comparisons data for PM
- Why (Why do this experiment and why use this method)
- Experiment: Number of Revisions / Number of Revisions + Varying number of constitutional principles used
- Figure 5 / Figure 6
- Experiment: Remove Critiques
- Figure 7
- better harmlessness scores for small models (10B)
- no noticeable different for large models
- Figure 7
- Experiment: RLHF
- train a HH model using human feedback labels only for helpfulness
- replace human feedback labels with model feedback labels for harmlessness
- all the RL runs in this paper use the same set of training prompts
- which consists of all the HF and model-generated prompts used for SL-CAI (Section 3.2)
- plus additional model-generated prompts: 491,142 for red team and 474,300 for helpfulness
- which consists of all the HF and model-generated prompts used for SL-CAI (Section 3.2)
- Results
- We didn’t see much benefit to using context distillation
- Figure 8 / Figure 9
- RL-CAI improve Harmless but reduce Helpfulness.
- RL-CAI models can be over-trained
- Experiment: Classify
- Figure 11 (Classify HHH)
- Figure 12 (Classify Harmful Behavior (multiple choice))
- Experiment: Number of Revisions / Number of Revisions + Varying number of constitutional principles used
- Other / Problem Need to Solve
- critique / revision problem
- critiques often provide inaccurate criticism
- the first revision often removes most harmful content from the original response, while subsequent revisions make only minor improvements.
- critique / revision problem
- Q
- These principles were chosen in a fairly ad hoc and iterative way for research purposes. In the future, we believe such principles should be redeveloped and refined by a larger set of stakeholders, and that they should also be adapted depending on the intended usage and location in which the model may be deployed. Since such a small number of bits of information are involved in these principles, it’s worth studying these bits carefully
- Do principles need to be iteratively online?
- Figure 8
- Most of company don’t care about Harmless. Can data augmentation skills such as Chain-of-Thought and Principle be used in Helpfulness?
- is that would be possible use latent space (z) as a goal like RL goal / Meta-learning / Mulite-task learning? z would be a principle embedding
- soft preference labels better results than hard labels
- [Kadavath et al., 2022].
- These principles were chosen in a fairly ad hoc and iterative way for research purposes. In the future, we believe such principles should be redeveloped and refined by a larger set of stakeholders, and that they should also be adapted depending on the intended usage and location in which the model may be deployed. Since such a small number of bits of information are involved in these principles, it’s worth studying these bits carefully
Written on May 15, 2023