Align Human Intent
What is Human intent & Human Preference in RLHF?
Language Model Problem
In InstructGPT/ChatGPT/GPT-4, they use RLHF to fine-tune the language model. OpenAI said they use RLHF to align human intent. When we unsupervised pre-train language model with , language model objective to maximize the likelihood:
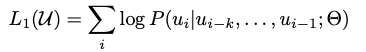
(GPT-1 paper)
On the application side, there might be instances where the language model can’t generate the intended text, causing a misalignment with the human intent. To address this issue, InstructGPT uses a technique called Reinforcement Learning with Human Feedback (RLHF) to fine-tune their model and ensure alignment with the human intent. By incorporating RLHF, InstructGPT can better understand the nuances of human language and produce more accurate responses, which ultimately leads to a better user experience.
What is Human intent & Human Preference?
Example 1
Here is an example from daily life:
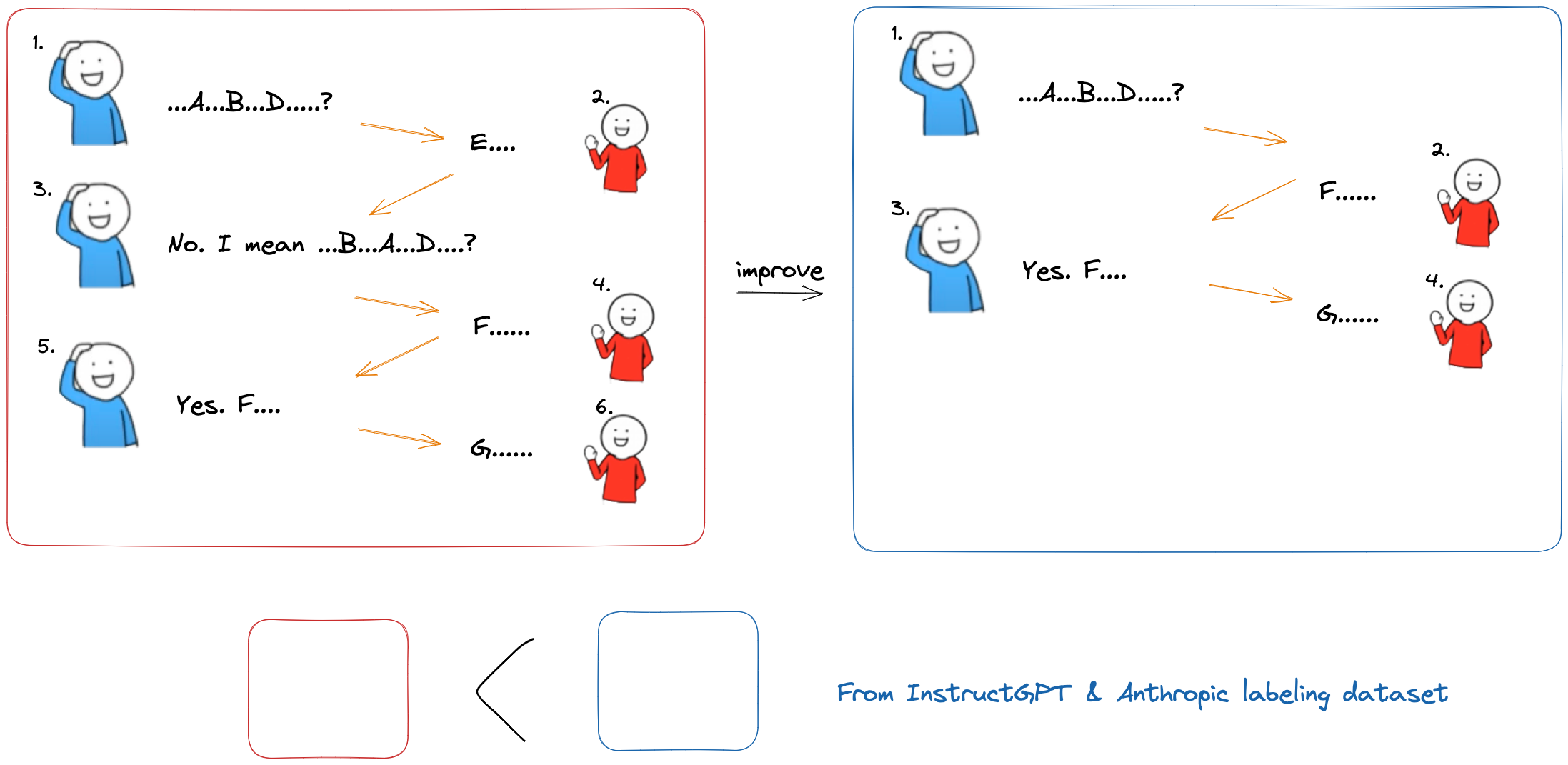
- Two people, BLUE and RED, are discussing a technical problem.
- BLUE realizes that RED is misunderstanding him, so he explains it using different words.
- This allows them to continue the conversation successfully.
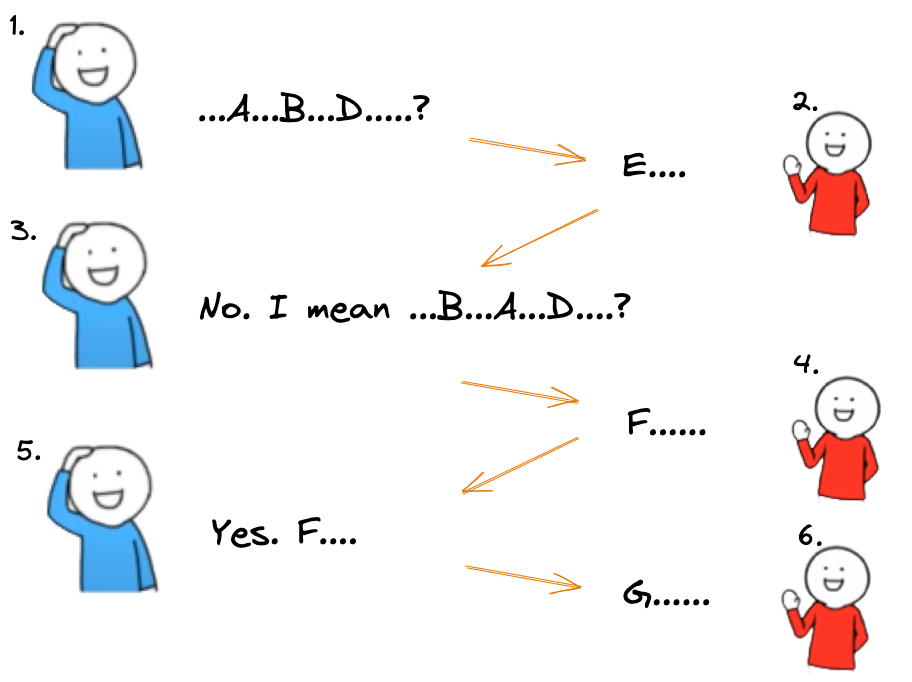
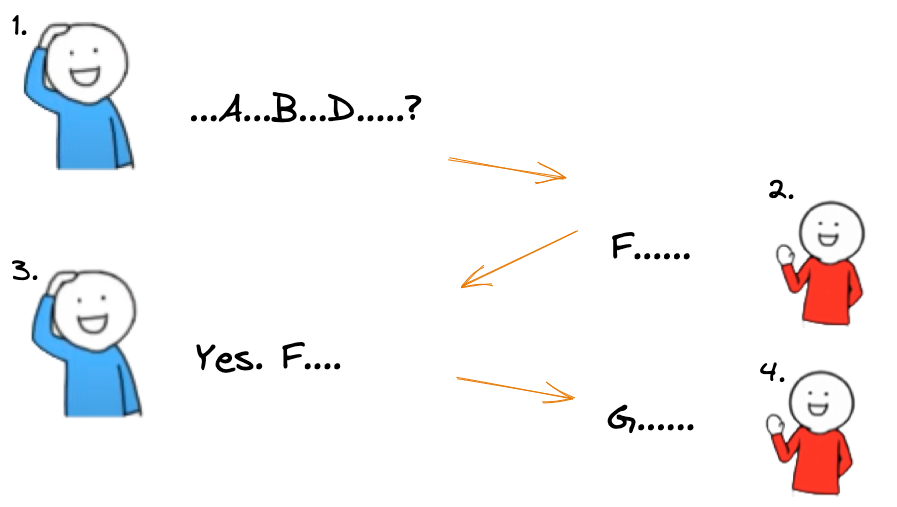
What if RED knew about BLUE’s problem or intention from the beginning?
Assuming RED had prior knowledge of BLUE’s intent, the conversations between the two parties would go more smoothly.
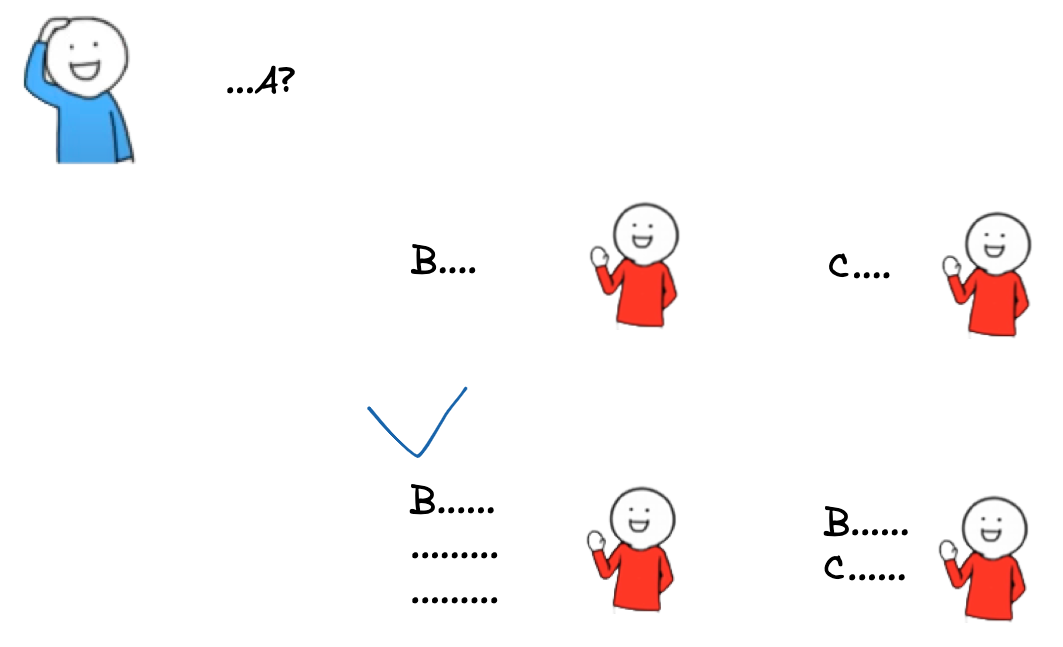
Example 2
When BLUE asks a question, RED has many ways to respond to BLUE.
For instance
- RED can choose to respond with a direct answer to the question.
- RED can choose to follow up with a related question to further clarify the original question or to gather more information.
- RED can example to illustrate a point related to the question.
- RED can choose to provide a more general response that is not directly related to the question but still provides valuable information to BLUE.
Labeling for Human intent & Human Preference?
When we engage with a chatbot, we expect it to be wise and knowledgeable about our needs. It is important for chatbots to be able to understand the context of the conversation and to provide helpful responses that meet our needs.
In the InstructGPT & Anthropic (Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback) paper, they hired people to label that data. This allowed them to create a more sophisticated training model that could help chatbots learn how to better understand the needs of their users and provide more helpful responses.