
Paper Note - Anthropic RLHF
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
paper source: https://arxiv.org/abs/2204.05862
Thesis Summary
To fully complete the RLHF product process, the following steps must be taken:
- Design the user interface.
- Create a user data collection process.
- Evaluate the quality of the collected data.
- Evaluate the Preference Model.
- Evaluate the Policy Model.
- Perform online iterative training.
This article is very useful for the company’s products, so it is important not to overlook any important information.
Paper Experiment Result: Trade-off between Helpful and Harmful
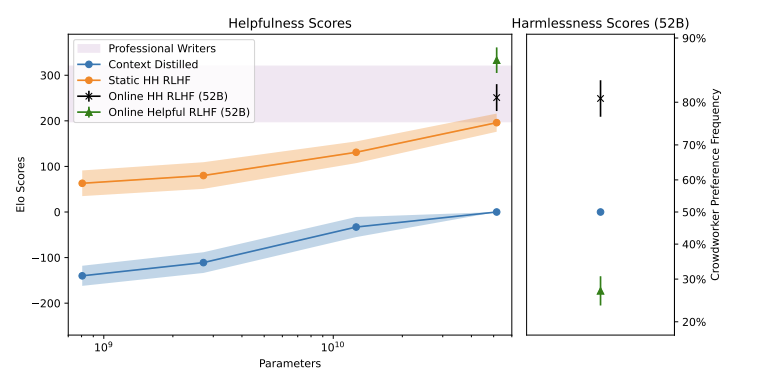
Useful content
- Important Points
- How to properly collect dataset / pretrain / RLHF PM Policy model, what problems will be encountered, and how to evaluate
- Human preference is actually vague. If the preference is helpful, PM can supervise helpfulness well.
- If the preference is accuracy, PM can logically supervise honesty well
- However, honesty is actually not suitable for human labeling
- First, the information is too limited, and honesty can be improved with more few-shot data
- When humans label A>B, they cannot clearly indicate which part is wrong, so targeted training is needed
- They will no longer receive appropriate punishment
- Any goal that is not the best source of information for human judgment
- However, honesty is actually not suitable for human labeling
- If the preference is accuracy, PM can logically supervise honesty well
- The best PM accuracy (human preference) is the upper limit of PPO, and the author hopes to approach it. RLHF channel has further room for improvement (Figure 34)
- How (Method)
- RLHF
- Why (Why do this experiment and why use this method)
- How to determine the impact of dataset cleanliness on PM & RLHF
- Figure 15
- How to estimate when Policy model is trained to the end?
- Figure 4
- How to evaluate the poor performance of PM/Policy model
- Figure 13
- RLHF on honesty may not be the best method
- That said, we do not currently expect RLHF to be the best approach to honesty
- 50-shot significantly improves honesty
- Want honesty? Simply increase the number of shots/prompt
- How to determine the impact of dataset cleanliness on PM & RLHF
- Other / Problem Need to Solve
- In future work, we plan to train policies to generate multiple steps, but this requires a separate model that generates the human side of the conversation, imitate the human side
- There is a gap between the PM score and the actual Elo situation.
- In the best case, PM accuracy can be perfectly reflected in RLHF’s Policy Model. But the results showed a gap. (Figure 34)
- Figure 4 (Experimental Purpose: Increase the impact of RLHF training)
- Setting
- Divide the dataset into two halves and train separate preference models on each half to ‘train PMs’ and ‘test PMs’
- In fact, PM is fixed, and training with RLHF uses train PMs to overfit and maximize the best human preference of train PMs
- y-axis
- PM score? what score? mean reward
- Left
- Robust up to about 150k training samples
- There is an approximately linear relationship between PM score gain and the square root of KL divergence
- Then, overfitting can be observed as the difference between training and testing PM scores.
- The training data to KL ratio (looks like 150k data = 3 DK^(1/2)) can be further studied (as DKL < 100 typically)
- Right
-
Trained and tested on 52BPM (all policy sizes)

-
- Setting
- Figure 13 (Analyze Linear √ DKL and Reward; impact of model size)
- The training curve in the √ KL and PM score plane, with an approximately linear relationship between these variables, especially in the left figure using the higher-performance 52B PM.
- Some instability was observed in smaller models, possibly because all of our PM training data was created using the 52B language model, which is often quite out of distribution for PMs with smaller LMs.
- Comparison of the left and right figures clearly shows that a small PM leads to poor performance of the Policy model
- Cool
- Top k samples versus the DKL = log(N/k)
- Another idea for Figure 13
- There are two possibilities for the so-called training failure: PM cannot be trained, resulting in Policy model cannot be trained / Policy model cannot be trained, but PM score cannot show any clues
- PM out of distribution = model is too small (neuron = 1) -> score is random -> LM is not helpful -> but the weight may not be poorly trained
-
Policy model is too small = simply cannot understand human preferences -> LM is poorly trained

- Figure 15 (Data Quality Verification)
- Data distribution
- Basic dataset (mainly distilled context model)
- Model enhanced by rejection sampling and
- Separate normalized distribution with useful data collected by our iterative “online” RLHF model.
- The tail of the distribution is supported by more RS and online models, which should allow the preference model to learn more subtle distinctions between high-quality responses and amplify the value of further data collection.
- Data distribution

Written on May 14, 2023